Home > Tech Gallery > CXL 3.0: Solving New Memory Problems in Data Centres (Part 2)

Time: December 17th, 2024




As a next-generation device interconnection standard protocol, Compute Express Link (CXL) has emerged as one of the most promising technologies in both industry and academia. It facilitates not only the expansion of memory capacity and bandwidth but also enhances heterogeneous interconnections and supports the decoupling of data centre resource pools. CXL's high bandwidth, low latency, substantial scalability, and maintenance of cache/memory consistency effectively address the "island" problem inherent in heterogeneous computing systems. This technology enables powerful computing capabilities that foster efficient collaboration within heterogeneous environments.
Delay Issues with CXL Technology
In recent years, the introduction of CXL technology has generated significant expectations within the industry. As a distributed memory technology, CXL 2.0 allows hosts to utilize their own directly connected DRAM while also accessing external DRAM via the CXL 2.0 interface. This capability to access external DRAM introduces increased latency when compared to local DRAM. While CXL is primarily characterized by low latency, it is important to acknowledge that there remains a latency gap when compared to the CPU's memory, cache, and registers.
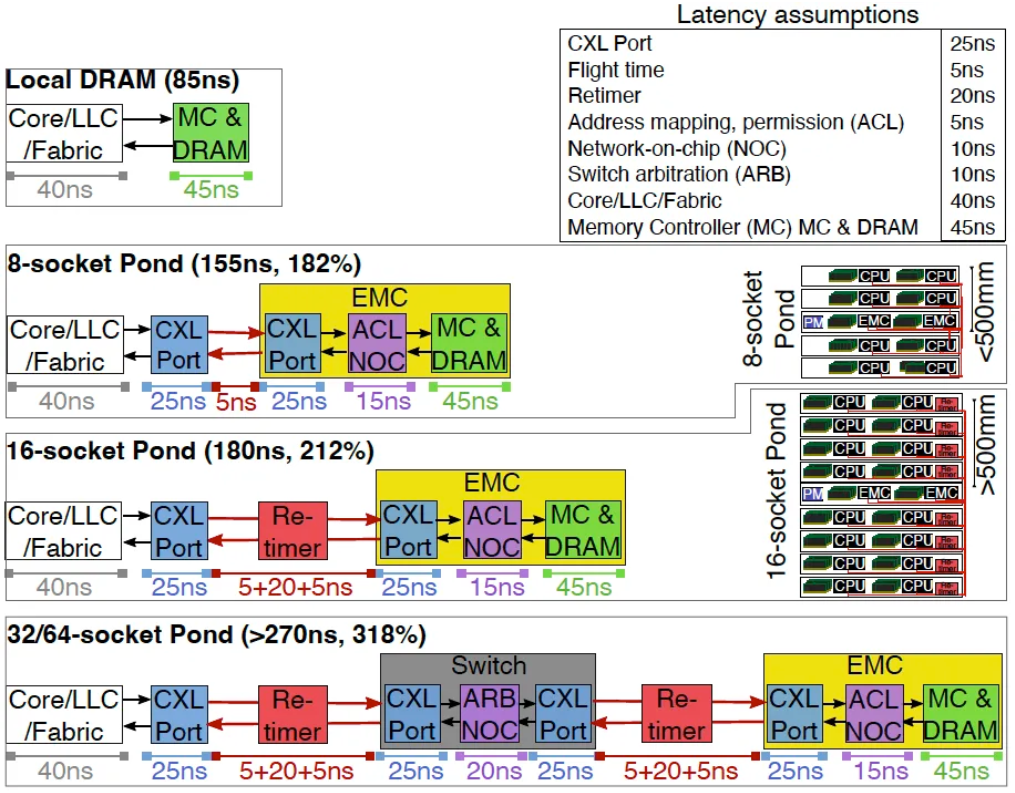
At the previous Hot Chips event, the CXL Alliance presented specific latency figures associated with CXL technology. The memory latency of CXL, independent of the CPU, ranges from approximately 170 to 250 nanoseconds, which is higher than that observed in non-volatile memory (NVM), disaggregated memory over network connections, solid-state drives (SSDs), and hard disk drives (HDDs), all of which are also independent of the CPU.
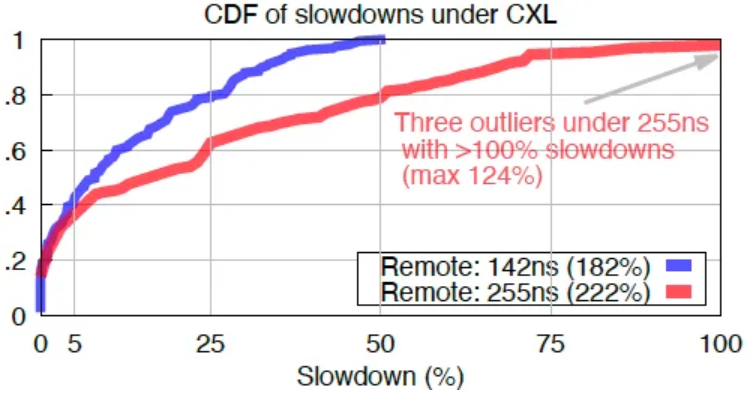
A report from Microsoft Azure indicates that CXL memory exhibits a latency gap relative to other CPU memory, caches, and registers, reported to be between 180% and 320%. For detailed latency values and proportions in various scenarios, please refer to the comprehensive introduction illustrated in the accompanying figure. Different application systems demonstrate varying sensitivities to latency, particularly applications that are latency-sensitive. The figure illustrates the effects of latency discrepancies across diverse CXL networking schemes on application performance. In scenarios lacking optimization, the overarching trend suggests a decline in performance across an increasing number of applications, although the precise percentage will require specific evaluation.
Looking ahead, the industry anticipates a significant improvement in CXL memory latency issues with the widespread implementation of PCIe 7.0/CXL 3.0; however, this is unlikely to occur before 2024-2025. In the interim, it remains possible to enhance performance by utilizing improved memory system management, scheduling, and monitoring software to mitigate the latency discrepancies between local and remote CXL memory.
At the previous Hot Chips event, the CXL Alliance presented specific latency figures associated with CXL technology. The memory latency of CXL, independent of the CPU, ranges from approximately 170 to 250 nanoseconds, which is higher than that observed in non-volatile memory (NVM), disaggregated memory over network connections, solid-state drives (SSDs), and hard disk drives (HDDs), all of which are also independent of the CPU.
A report from Microsoft Azure indicates that CXL memory exhibits a latency gap relative to other CPU memory, caches, and registers, reported to be between 180% and 320%. For detailed latency values and proportions in various scenarios, please refer to the comprehensive introduction illustrated in the accompanying figure. Different application systems demonstrate varying sensitivities to latency, particularly applications that are latency-sensitive. The figure illustrates the effects of latency discrepancies across diverse CXL networking schemes on application performance. In scenarios lacking optimization, the overarching trend suggests a decline in performance across an increasing number of applications, although the precise percentage will require specific evaluation.
Looking ahead, the industry anticipates a significant improvement in CXL memory latency issues with the widespread implementation of PCIe 7.0/CXL 3.0; however, this is unlikely to occur before 2024-2025. In the interim, it remains possible to enhance performance by utilizing improved memory system management, scheduling, and monitoring software to mitigate the latency discrepancies between local and remote CXL memory.
Analysis of Delay Values in Local and CXL Memory Resource Expansion
Analysis of the Impact of Microsoft Azure CXL Memory on Applications
Solution for delay in CXL technology
The advancement of CXL (Compute Express Link) technology has prompted an increasing number of enterprises to adopt heterogeneous layered memory systems that are compatible with CXL. Meta has proposed a hierarchical memory classification, segmenting it into three categories: "hot" memory, designated for critical tasks such as real-time data analysis; "warm" memory, which experiences infrequent access; and "cold" memory, allocated for extensive data storage. "Hot" memory resides in the native DDR memory, whereas "cold" memory is assigned to CXL memory. Nonetheless, current software applications may lack the capability to adequately differentiate between "hot" and "cold" memory. As native memory reaches capacity, it encroaches upon CXL memory, transforming what was originally intended as "cold" memory into "hot" memory. A significant challenge persists at the operating system and software level: effectively identifying "cold" memory pages and proactively transferring them to CXL memory to free up space within the native DDR memory.
To enhance performance within such systems, Meta has undertaken an exploration of an alternative approach to memory page management, departing from conventional local DRAM practices. This approach aims to address the thermal characteristics of memory pages through a Linux kernel extension known as Transparent Page Placement (TPP). Acknowledging the latency disparity between CXL main memory and local memory—as is common in distributed storage systems employing tiered management for flash and hard disk drives—Meta introduced the Multi-Tier Memory concept in its TPP paper. This framework seeks to assess the volume of data residing in memory, distinguishing between hot, warm, and cold data based on varying levels of activity. Subsequently, it identifies mechanisms for positioning hot data in the fastest memory, cold data in the slowest memory, and warm data in the intermediate memory.
The TPP design space encompasses four primary domains:
To enhance performance within such systems, Meta has undertaken an exploration of an alternative approach to memory page management, departing from conventional local DRAM practices. This approach aims to address the thermal characteristics of memory pages through a Linux kernel extension known as Transparent Page Placement (TPP). Acknowledging the latency disparity between CXL main memory and local memory—as is common in distributed storage systems employing tiered management for flash and hard disk drives—Meta introduced the Multi-Tier Memory concept in its TPP paper. This framework seeks to assess the volume of data residing in memory, distinguishing between hot, warm, and cold data based on varying levels of activity. Subsequently, it identifies mechanisms for positioning hot data in the fastest memory, cold data in the slowest memory, and warm data in the intermediate memory.
The TPP design space encompasses four primary domains:
1. Lightweight downgrade to CXL memory,
2. Decoupling distribution and recovery paths,
3. Elevating hot pages to the local node, and
4. Page type-aware memory allocation.
Meta's TPP represents a kernel-mode solution leveraging transparent monitoring and placement of page temperature. This protocol operates in conjunction with Meta's Chameleon memory tracking tool, functioning within the Linux user space, thereby facilitating the performance tracking of CXL memory across applications. Meta has assessed TPP using various production workloads, optimizing the placement of "hotter" pages in local memory while relocating "colder" pages from CXL memory. The findings demonstrate that TPP can enhance performance by approximately 18% in comparison to applications running on the default Linux configuration. Furthermore, TPP shows improvements ranging from 5% to 17% relative to two leading existing techniques for tiered memory management: NUMA balancing and automatic tiering.
Meta's TPP represents a kernel-mode solution leveraging transparent monitoring and placement of page temperature. This protocol operates in conjunction with Meta's Chameleon memory tracking tool, functioning within the Linux user space, thereby facilitating the performance tracking of CXL memory across applications. Meta has assessed TPP using various production workloads, optimizing the placement of "hotter" pages in local memory while relocating "colder" pages from CXL memory. The findings demonstrate that TPP can enhance performance by approximately 18% in comparison to applications running on the default Linux configuration. Furthermore, TPP shows improvements ranging from 5% to 17% relative to two leading existing techniques for tiered memory management: NUMA balancing and automatic tiering.
|
Workload/Throughput (%) (normalized to Baseline)
|
Default Linux
|
TPP
|
NUMA Balancing
|
Auto Tiering
|
|
Web1 (2:1)
|
83.5
|
99.5
|
82.8
|
87.0
|
|
Cache1 (2:1)
|
97.0
|
99.9
|
93.7
|
92.5
|
|
Cache1 (1:4)
|
86.0
|
99.5
|
90.0
|
Fails
|
|
Cache2 (2:1)
|
98.0
|
99.6
|
94.2
|
94.6
|
|
Cache2 (1:4)
|
82.0
|
95.0
|
78.0
|
Fails
|
|
Data Warehouse (2:1)
|
99.3
|
99.5
|
-
|
-
|
The TPP protocol is more effective than other protocols in reducing memory access latency
The TPP initiative aims to reduce memory access latency and enhance application throughput. It is anticipated that, over time, technological delays associated with CXL will be significantly mitigated.
CXL 3.0: Enters Heterogeneous Interconnection
The CXL (Compute Express Link) alliance has introduced the CXL 3.0 standard, which incorporates enhanced structural functionality and management. This iteration offers improvements in memory pools, consistency, and peer-to-peer communication, leading to significant advancements overall. Notably, the data transmission rate has doubled to 64 GT/s, while latency remains unchanged compared to CXL 2.0. Moreover, CXL 3.0 maintains backward compatibility with previous standards, including CXL 2.0, CXL 1.1, and CXL 1.0, thereby facilitating the creation of heterogeneous and composable server architectures.
With CXL 3.0, the switch now supports a wider array of topological configurations. Unlike CXL 2.0, which primarily allowed for fan-out using CXL.mem devices—where the host accessed memory resources from external devices—CXL 3.0 permits the utilization of Spine/Leaf and other topological networks across one or multiple server racks. Furthermore, the theoretical limitation on the number of switch ports for CXL 3.0 equipment, host machines, and switches has been increased to 4,096. These developments significantly enhance the potential scalability of CXL networks, expanding capabilities from individual servers to comprehensive server rack infrastructures.
With CXL 3.0, the switch now supports a wider array of topological configurations. Unlike CXL 2.0, which primarily allowed for fan-out using CXL.mem devices—where the host accessed memory resources from external devices—CXL 3.0 permits the utilization of Spine/Leaf and other topological networks across one or multiple server racks. Furthermore, the theoretical limitation on the number of switch ports for CXL 3.0 equipment, host machines, and switches has been increased to 4,096. These developments significantly enhance the potential scalability of CXL networks, expanding capabilities from individual servers to comprehensive server rack infrastructures.
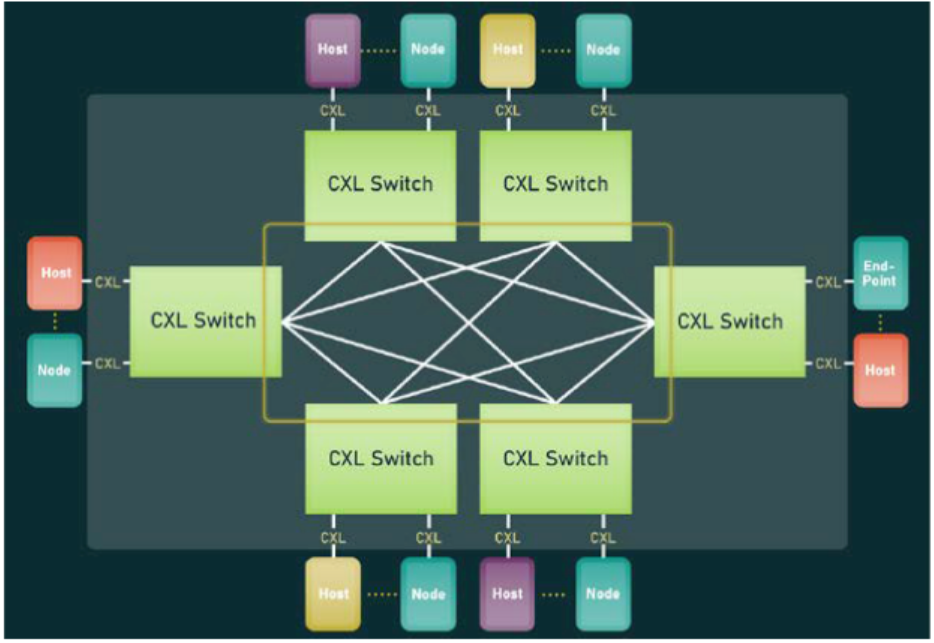
CXL structure: non-tree topology
CXL 3.0—Fabric Capability:
1. Support for multiple headers and fabric connectivity devices.
2. Improvement of fabric management capabilities.
3. Provision for a combinable classification infrastructure.
CXL 3.0: Better Scalability and Higher Resource Utilization:
CXL 3.0: Better Scalability and Higher Resource Utilization:
●
Enhanced Memory Pool
CXL 2.0 introduces a memory pool that allows multiple hosts to access the device's memory, with each host being assigned a dedicated memory segment. In contrast, CXL 3.0 has implemented real memory-sharing capabilities. The enhanced consistency semantics now permit multiple hosts to maintain a consistent copy of a shared memory segment. In instances where changes occur at the device level, reverse invalidation can be employed to ensure synchronization among all hosts.
● Support for Multi-Level Switching
● Support for Multi-Level Switching
Building upon CXL 2.0, the latest version expands support for switch protocols, permitting only a single switch between a host and its respective devices. However, the introduction of multilayer switching enables the configuration of multiple layers of switches, allowing for complex arrangements in which switches can interconnect to other switches. This significantly enhances the variety and complexity of supported network topologies.
● Enhanced Consistency
● Enhanced Consistency
CXL has revised the cache coherence protocol for memory devices, moving away from the previous memory consistency method that favoured control by one entity. This bias-based coherency approach primarily aimed to simplify the protocol. Rather than relying on shared memory space access control, the new methodology assigns responsibility for access rights to either the host or the device. The upgraded consistency method more accurately reflects the principles of memory sharing, promoting a peer role approach between hosts and devices. Additionally, CXL notifies the host of any changes in the device's cache, enabling the host to subsequently read the updated data.
● Improved Software Functionality
● Improved Software Functionality
CXL 3.0 has further enhanced host-device functionality by eliminating previous limitations concerning connections to a single CXL downstream of the root port for Type-1 and Type-2 devices.
Under CXL 2.0, only one processing device could be supported downstream from the root port. However, CXL 3.0 has fully removed these constraints, allowing the CXL root port to support a complete mixed configuration of Type-1, Type-2, and Type-3 devices. This advancement facilitates the connection of multiple accelerators to a single switch, thereby increasing density (more accelerators per host) and enhancing the utility of the new point-to-point transmission capabilities.
CXL 3.0 - Key Characteristics:
Under CXL 2.0, only one processing device could be supported downstream from the root port. However, CXL 3.0 has fully removed these constraints, allowing the CXL root port to support a complete mixed configuration of Type-1, Type-2, and Type-3 devices. This advancement facilitates the connection of multiple accelerators to a single switch, thereby increasing density (more accelerators per host) and enhancing the utility of the new point-to-point transmission capabilities.
CXL 3.0 - Key Characteristics:
1. The bandwidth has been effectively doubled to 64 GT/s while maintaining the same delay performance as CXL 2.0.
2. Furthermore, it ensures full backward compatibility with previous versions, specifically 2.0, 1.1, and 1.0 specifications.
The introduction of memory sharing and direct device-to-device communication capabilities in CXL 3.0 significantly improves the communication dynamics within heterogeneous networks. This advancement enables the host CPU and various devices to collaborate on the same dataset, thereby minimizing unnecessary data disruption and duplication. For instance, as illustrated in the accompanying figure, Host 1, Host 3, and other relevant devices share a common data copy, denoted as S1; Host 1 and Host 2 share another copy, referred to as S2; while Host 2 and Host # access yet another shared data copy, labelled S3.
The introduction of memory sharing and direct device-to-device communication capabilities in CXL 3.0 significantly improves the communication dynamics within heterogeneous networks. This advancement enables the host CPU and various devices to collaborate on the same dataset, thereby minimizing unnecessary data disruption and duplication. For instance, as illustrated in the accompanying figure, Host 1, Host 3, and other relevant devices share a common data copy, denoted as S1; Host 1 and Host 2 share another copy, referred to as S2; while Host 2 and Host # access yet another shared data copy, labelled S3.
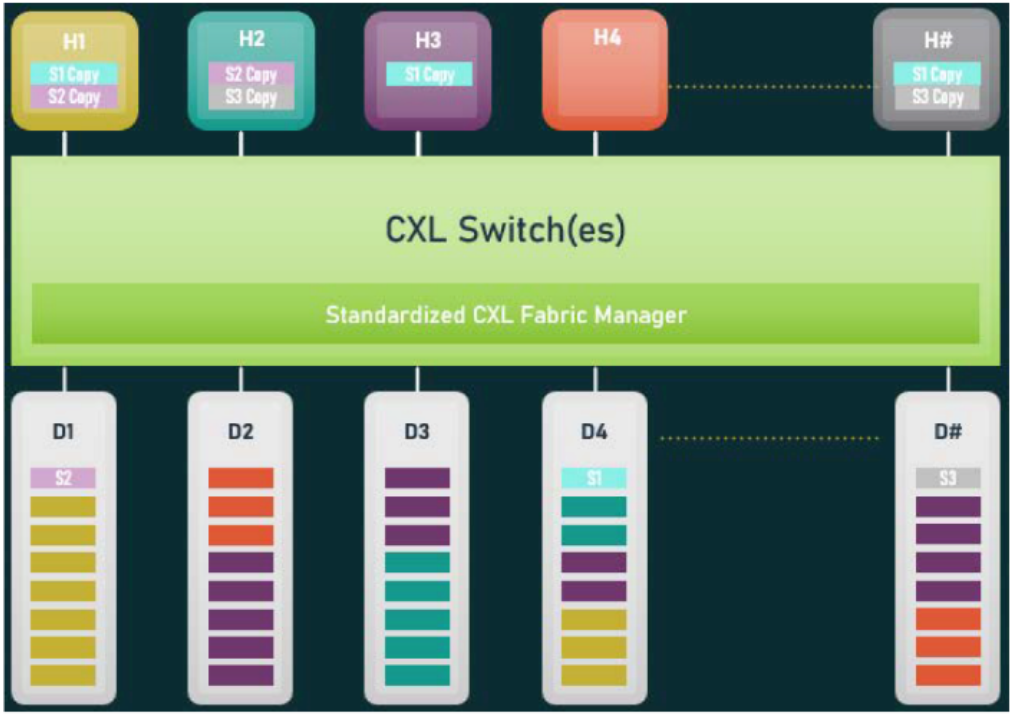
CXL 3.0 Memory Pooling and Sharing
One notable instance of data sharing in contemporary environments is evident in the application of artificial intelligence workloads, such as the deep learning recommendation systems developed by technology giants like Google and Meta. These systems, characterized by billions of parameters, often replicate model data across numerous servers. Once a user request is received, the inference operation is initiated. With the implementation of CXL 3.0 memory sharing, substantial AI models can reside in various central memory devices, facilitating access from multiple devices. This setup allows for the continuous training of models utilizing real-time mobile user data, with potential updates disseminated across the CXL Exchange network. Such advancements can significantly decrease DRAM costs and enhance performance by an order of magnitude.
Furthermore, the utilization of CXL 3.0 enhances consistency features, thereby achieving loose coupling among heterogeneous hardware accelerators, and enabling collaborative functionality. In this context, we leverage CXL 3.0 for GPU and FPGA memory sharing. The direct bypass of the PCIe bus allows for effective data communication and joint completion of mathematical operations. For instance, an FPGA is tasked with decompressing a file comprising 1.6GB of double-precision values, which the GPU subsequently employs to perform integration calculations on the input data. This underscores the interaction patterns of workloads within anticipated future heterogeneous systems, where FPGA demonstrates significant performance advantages for sequential and pipelined computations, while the GPU excels in branching and memory stride calculations.
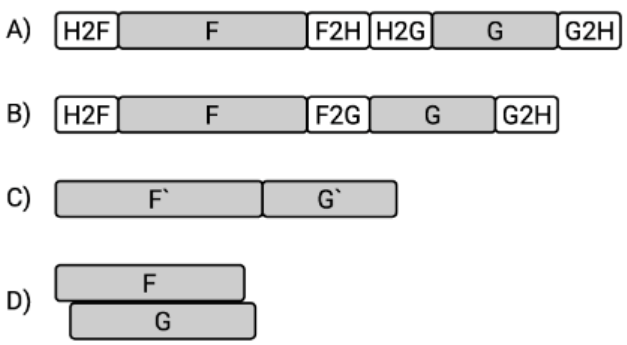
Current practices with PCIe necessitate the use of main memory for intermediary data transfers between the FPGA and GPU. Specifically, sharing data between these accelerators involves copying data from the FPGA to the CPU, followed by another transfer from the CPU to the GPU. The specific workflow is as follows:
1. FPGA Host machine (H2F) memory transfer
2. FPGA Kernel execution (F)
3. FPGA transfer to host (F2H)
4. Host to GPU transmission (H2G)
5. GPU Kernel execution (G)
6. GPU transfer to the host (G2H)
CXL supports the establishment of a cache-consistent unified memory space among hosts and devices. In traditional accelerator designs utilizing PCIe, it is necessary to program explicit data movement requests for object memory management involving the host and device. In contrast, unified memory enables implicit operations on the same data objects by both host and device, thereby simplifying memory management. Once data is loaded onto the accelerator device, CXL and DMA PCIe transfer methods facilitate local access. In this latter instance, data buffers are explicitly moved to the local device memory. CXL-accessed memory addresses are cached locally, permitting efficient retrieval during subsequent accesses. The unified memory model provided by CXL selectively transfers only the cache lines that have been accessed by the accelerators, unlike PCIe DMA, which requires transmitting the entire address range of the transmission buffer.
The cache consistency and memory sharing capabilities of CXL will enable direct interaction among heterogeneous system hosts, specifically the CPU, FPGA, and GPU, without necessitating preliminary data transfer to the host. This advancement allows for the direct transmission of data from FPGA to GPU, replacing F2H and H2G transitions. Furthermore, this approach will allow kernels to access the local device's shared memory directly. Consequently, the earlier steps (H2F, F2G, and G2H) may be omitted, streamlining operations to focus solely on FPGA kernel computations (F0) and GPU kernel executions (G0). Although there may be a slight increase in runtime due to cache loading requirements, this additional time can be mitigated if the application is designed to pre-fetch data locally during pipeline execution.
CXL supports the establishment of a cache-consistent unified memory space among hosts and devices. In traditional accelerator designs utilizing PCIe, it is necessary to program explicit data movement requests for object memory management involving the host and device. In contrast, unified memory enables implicit operations on the same data objects by both host and device, thereby simplifying memory management. Once data is loaded onto the accelerator device, CXL and DMA PCIe transfer methods facilitate local access. In this latter instance, data buffers are explicitly moved to the local device memory. CXL-accessed memory addresses are cached locally, permitting efficient retrieval during subsequent accesses. The unified memory model provided by CXL selectively transfers only the cache lines that have been accessed by the accelerators, unlike PCIe DMA, which requires transmitting the entire address range of the transmission buffer.
The cache consistency and memory sharing capabilities of CXL will enable direct interaction among heterogeneous system hosts, specifically the CPU, FPGA, and GPU, without necessitating preliminary data transfer to the host. This advancement allows for the direct transmission of data from FPGA to GPU, replacing F2H and H2G transitions. Furthermore, this approach will allow kernels to access the local device's shared memory directly. Consequently, the earlier steps (H2F, F2G, and G2H) may be omitted, streamlining operations to focus solely on FPGA kernel computations (F0) and GPU kernel executions (G0). Although there may be a slight increase in runtime due to cache loading requirements, this additional time can be mitigated if the application is designed to pre-fetch data locally during pipeline execution.
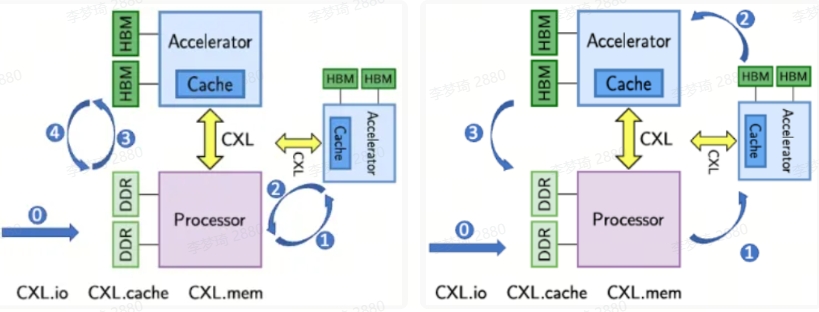
Implementing direct memory sharing through cache coherence
Using local memory as an intermediate transmission medium
CXL Communication Logic Diagram of Memory-Sharing Heterogeneous Systems
Furthermore, as the processes of file extraction and integration occur sequentially, the optimal integration strategy involves executing the entire program in a data flow manner. The simultaneous utilization of FPGA and GPU accelerators enables pipelined communication computing, thereby reducing overall execution time. Applications that operate in a pipelined fashion benefit from enhanced cache coherence, memory sharing, high bandwidth, and low latency. The characteristics of CXL (Compute Express Link) facilitate heterogeneous computing models. The close integration of FPGA and GPU accelerators can significantly enhance application completion times compared to traditional baseline environments.
From the above discussion, it is evident that the significance of CXL extends beyond memory alone; it encompasses various computing forms, including memory, networking, storage, and accelerator cards. Composable server architectures, specifically the Domain-Specific Architecture (DSA), refer to the decomposition of servers into discrete components organized in groups that can be dynamically allocated based on workload requirements. Consequently, data centre racks can function as computing units, allowing customers to select various combinations of cores, memory, and AI processing capabilities. This vision represents a transformative approach to server design and cloud computing. Nevertheless, the implementation of this model presents numerous intricate engineering challenges, with the protocol being of utmost priority. This urgency has contributed to the rapid emergence of CXL 2.0 and 3.0 standards.
Currently, the primary application scenarios for CXL remain centred on memory expansion and resource pooling. Given the present dynamics within the server market, low-core count CPUs will continue to rely on conventional DDR channel configurations for DIMM memory. In contrast, high-core count CPUs will adapt flexibly based on key parameters such as system costs, capacity, power consumption, and bandwidth requirements. CXL memory represents a core advantage of this technology. The potential for performance and cost-effectiveness improvements through memory sharing is virtually limitless. Initial implementations of memory pools can yield a reduction in overall DRAM demand by approximately 10%. Furthermore, a lower latency memory pool could result in savings of around 23% in multi-tenant cloud environments, while memory sharing has the capacity to further reduce DRAM demand by over 35%. Such savings translate into billions of dollars spent annually on DRAM within data centres.
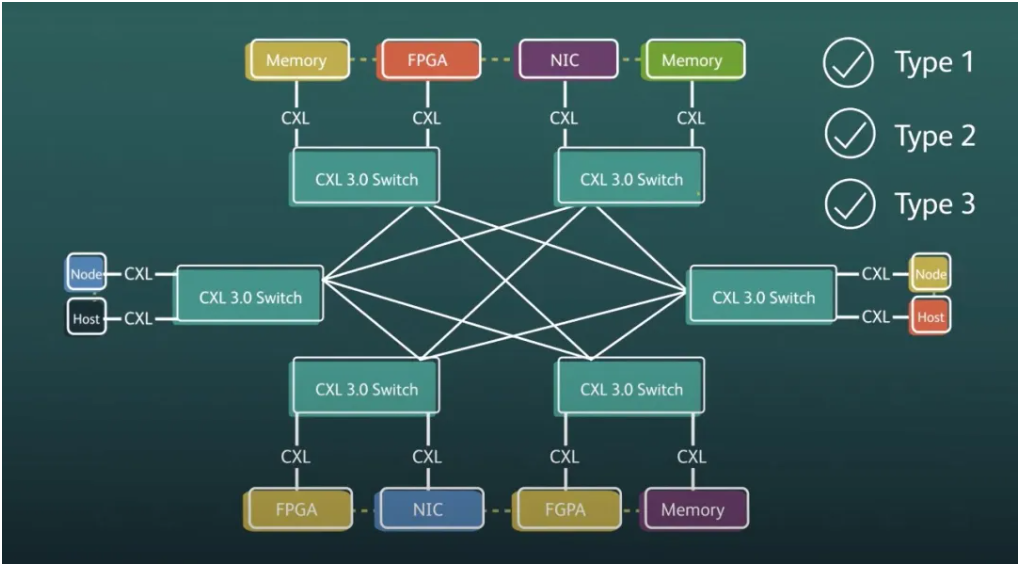
CXL 3.0 achieves interconnection and interoperability among various units of heterogeneous systems
The emergence and popularization of horizontally expanding cloud computing data centres have significantly transformed the market landscape. In this new paradigm, the emphasis has shifted from prioritizing faster CPU cores to the economic and efficient delivery of overall computing performance and its integration. The specialization of computing resources has become a prevailing trend, leading to the dominance of heterogeneous computing within data centres. Various accelerators, such as dedicated ASICs, FPGAs, GPUs, DPUs, and IPUs, are now capable of delivering performance increases exceeding tenfold for specific tasks, utilizing fewer transistors.
The current approach of designing chips to accommodate an entire workload is being supplanted by a more cost-effective strategy that favours the creation of Domain Specific Architecture (DSA) chips, which can be configured to meet the unique demands of particular workloads. By integrating software solutions with heterogeneous computing systems—comprising CPUs along with either integrated or independent GPU, FPGA, or DSA processors—organizations can construct large systems that possess tailored functionalities for diverse applications, such as networking, storage, virtualization, security, databases, video imaging, and deep learning.
In contemporary computing paradigms, the architecture of computing systems has evolved from isolated chips or servers to encompass entire data centres, which now function as the primary computing units. The implementation of a unified device interconnection system, termed Unified Interconnected Fabric, facilitates the interoperability of multiple processors, accelerators, and resource pools in heterogeneous environments.
As a leader in the development of intelligent computing centres, Ruijie Network is committed to delivering innovative product solutions and services to its clients, thereby addressing the demands of the emerging intelligent computing era in partnership with its customers.
Featured blogs
- Ruijie RALB Technology: Revolutionizing Data Center Network Congestion with Advanced Load Balancing
- CXL 3.0: Solving New Memory Problems in Data Centres (Part 2)
- Multi-Tenant Isolation Technology in AIGC Networks—Data Security and Performance Stability
- Multi-dimensional Comparison and Analysis of AIGC Network Card Dual Uplink Technical Architecture
- A Brief Discussion on the Technical Advantages of the LPO Module in the AIGC Computing Power Network






